
Why ditch Logstash?

Logstash runs on JVM and consumes a hefty amount of resources to do so. Many discussions have been floating around regarding Logstash’s significant memory consumption. Obviously this can be a great challenge when you want to send logs from a small machine (such as AWS micro instances) without harming application performance. To overcome this memory issue people usually use Filebeats that collects data from individual VMs and then send it to the aggregator, adding one more stack to maintain in your pipeline.
Why Fluentd?
- Memory issues? No more: Fluentd is written in a combination of C language and Ruby, and requires very little system resource. The vanilla instance runs on 30–40MB of memory and can process 13,000 events/second/core. Fluentd also has a lighter version literally made available to run on embedded devices, Fluent Bit promises to run on memory consumption of about 450KB!!
- 500+ Plugins: Fluentd has a flexible plugin system that allows the community to extend its functionality. Our 500+ community-contributed plugins connect dozens of data sources and data outputs. By leveraging the plugins, you can start making better use of your logs right away.
- Built-in Reliability: Fluentd supports memory- and file-based buffering to prevent inter-node data loss. Fluentd also supports robust failover and can be set up for high availability. 2,000+ data-driven companies rely on Fluentd to differentiate their products and services through better use and understanding of their log data.
- Open Source, Open Source, Open Source: Fluentd is an open-source data collector, which lets you unify the data collection and consumption for better use and understanding of data.
Getting your hands dirty
Prerequisites
- Docker
- Node.js
Yes, That’s all
Step 1: Create the docker-compose file
To sum up the docker image, it builds a docker file from ./fluentd folder, we’ll be coming to this in a moment, then attaches a volume to ./fluentd/conf. After that pulls elastic search 7.6.2, I could not get the latest elastic search working but that issue might be fixed soon. And then sets up Kibana
Step 2: Writing the Fluentd Dockerfile
Step 3: Fluentd Configuration File
The configuration file consists of the following directives:
1. source: Fluentd’s input sources are enabled by selecting and configuring the desired input plugins using source directives. Fluentd’s standard input plugins include HTTP and forward. HTTP turns Fluentd into an HTTP endpoint to accept incoming HTTP messages whereas forward turns Fluentd into a TCP endpoint to accept TCP packets.
2. match: The “match” directive looks for events with matching tags and processes them. The copy output plugin copies events to multiple outputs.
3. filter: A Filter aims to behave like a rule to pass or reject an event.
4. system directives set system-wide configuration.
5. label directives group the output and filter for internal routing
6. @include directives include other files.
Step 4: Run them all
Run docker-compose upand wait for the output. Then please visit http://localhost:5601/ in your browser. Then, you need to set up the index name pattern for Kibana. Please specify fluentd-* to Index name or pattern and press Create button. Then, go to Discover the tab to seek for the logs. Now we’ll be sending in the logs with node.
Step 5: Minimal Node setup
Run npm init -yand paste the following in the index.js. It uses fluent-logger to connect to the Fluentd instance and send in data to Fluentd. Agree I could create a loop but hey, minimal?! Run the following and watch your Kibana output the log.
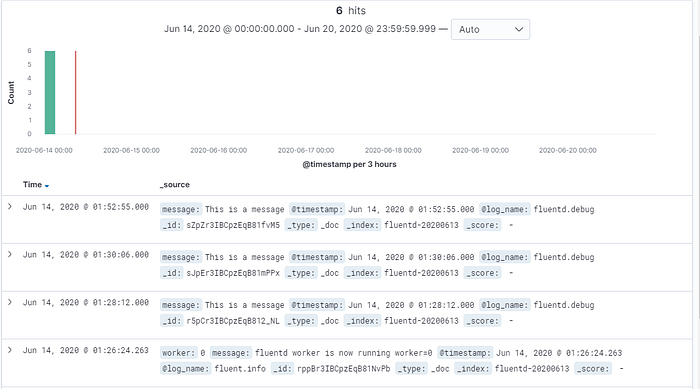
Now you have another achievement under your belt ❤ ❤ ❤. Stay tuned for more. Repo link attached below.
